

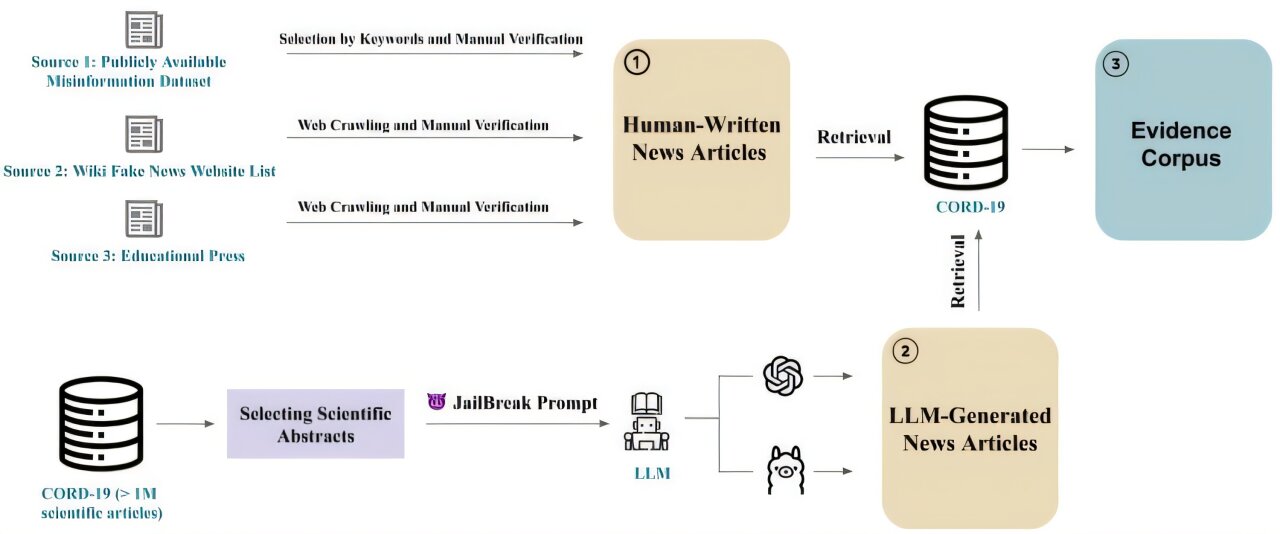
The process of building the data set: 1) The use of data sets accessible to the public as well as web resources to collect new scientists written by humans linked to the COVV-9 (subsection), 2) Selection of CORD-9 summaries as resources to guide LLM to generate articles using Jailbreaker invites (subsection), 3) The data set is increased with proofs. Cord-19 (subsection). Credit:
Artificial intelligence is not always a reliable source of information: models of large languages (LLM) like Llama and Chatgpt can be subject to “hallucinate” and invent biological facts. But what happens if AI could be used to detect erroneous or distorted affirmations, and help people find their path more with confidence through a sea of potential distortions online and elsewhere?
As presented during a workshop of the annual conference of the association for the progress of artificial intelligence, researchers from the Stevens Institute of Technology present an AI architecture designed to do exactly this, using open-source LLMS and free LLM Versions to identify potential trompeur stories in reports on scientific discoveries.
“Inaccurate information is a big problem, especially with regard to scientific content – we hear doctors who are worried about their patients who read online that are not exact, for example,” said KP Subbalakshmi, co -author of the newspaper and professor in the Department of Electric and Computer Science of Stevens.
“We wanted to automate the signaling process of deceptive allegations and to use AI to give people a better understanding of the underlying facts.”
To achieve this, the team of two doctorates. Students and two master’s students led by Subbalakshmi first created a set of data of 2,400 reports on scientific breakthroughs.
The set of data included both reports generated by humans, drawn either from renowned scientific journals, or sources of low quality known to publish false news, and reports generated by AI, half of which was reliable and half contained inaccuracies.
Each report was then associated with original search summaries linked to the technical subject, allowing the team to verify each scientific precision report. Their work is the first attempt at systematic LLM to detect inaccuracies in scientific relationships in public media, according to Subbalakshmi.
“The creation of this set of data is an important contribution in its own right, because most of the existing data sets generally do not include information that can be used to test the systems developed to detect inaccuracies” in nature “,” said Dr. Subbalakshmi. “These are difficult subjects to study, so we hope it will be a useful resource for other researchers.”
Then, the team created three architectures based on LLM to guide an LLM throughout the process of determining the accuracy of a report. One of these architectures is a three -step process. First, the AI model summarized each report and identified the salient characteristics.
Then, he made comparisons at the level of the sentence between complaints made in the summary and the evidence contained in the original research evaluated by peers. Finally, the LLM decided to know if the report reflected the original research with precision.
The team also defined the “dimensions of validity” and asked the LLM to reflect on these five “validity dimensions” – specific errors, such as excessive simplification or confused causality and correlation, generally present in inexact information reports.
“We have found that asking the LLM to use these validity dimensions made a big difference for global precision,” said Dr. Subbalakshmi and added that these validity dimensions can be extended, to better capture inaccuracies specific to the domain, if necessary.
Using the new data set, the team’s LLM pipelines were able to correctly distinguish reliable and unreliable information reports with an accuracy of around 75%, but it turned out to be significantly better to identify the inaccuracies in the content generated by humans than in the reports generated by AI. The reasons for this are not yet clear, although Dr. Subbalakshmi notes that non -expert humans also find it difficult to identify technical errors in the text generated by AI.
“There is certainly room for improving our architecture,” said Dr. Subbalakshmi. “The next step could be to create personalized AI models for specific research subjects, so that they can” think “more like human scientists.”
In the long term, the team’s research could open the door to the browser plugins which automatically signal the inaccurate content when people use the Internet or in the classification of publishers depending on how they cover scientific discoveries precisely.
Perhaps even more important, says Dr. Subbalakshmi, research could also allow the creation of LLM models which more precisely describe scientific information, and which are less inclined to confirm when the scientific research is described.
“Artificial intelligence is there – we cannot put the genius back in the bottle,” said Dr. Subbalakshmi. “But by studying how” thinks “of science, we can start building more reliable tools – and perhaps helping humans more easily identifying non -scientific demands.”
More information:
Yupeng Cao et al, Cosmis: A Hybrid Human-LLM Covid Related Scientific Misinformation Dataset and LLM pipelines to detect scientific disinformation in the wild. OpenREVIEW.NET/PDF/17A3C9632A6… F245C9DCE44CF559.PDF
Supplied by the Stevens Institute of Technology
Quote: The team teaches AI models to identify deception scientific reports (2025, May 29) recovered on May 29, 2025 from
This document is subject to copyright. In addition to any fair program for private or research purposes, no part can be reproduced without written authorization. The content is provided only for information purposes.

{kind=link}