

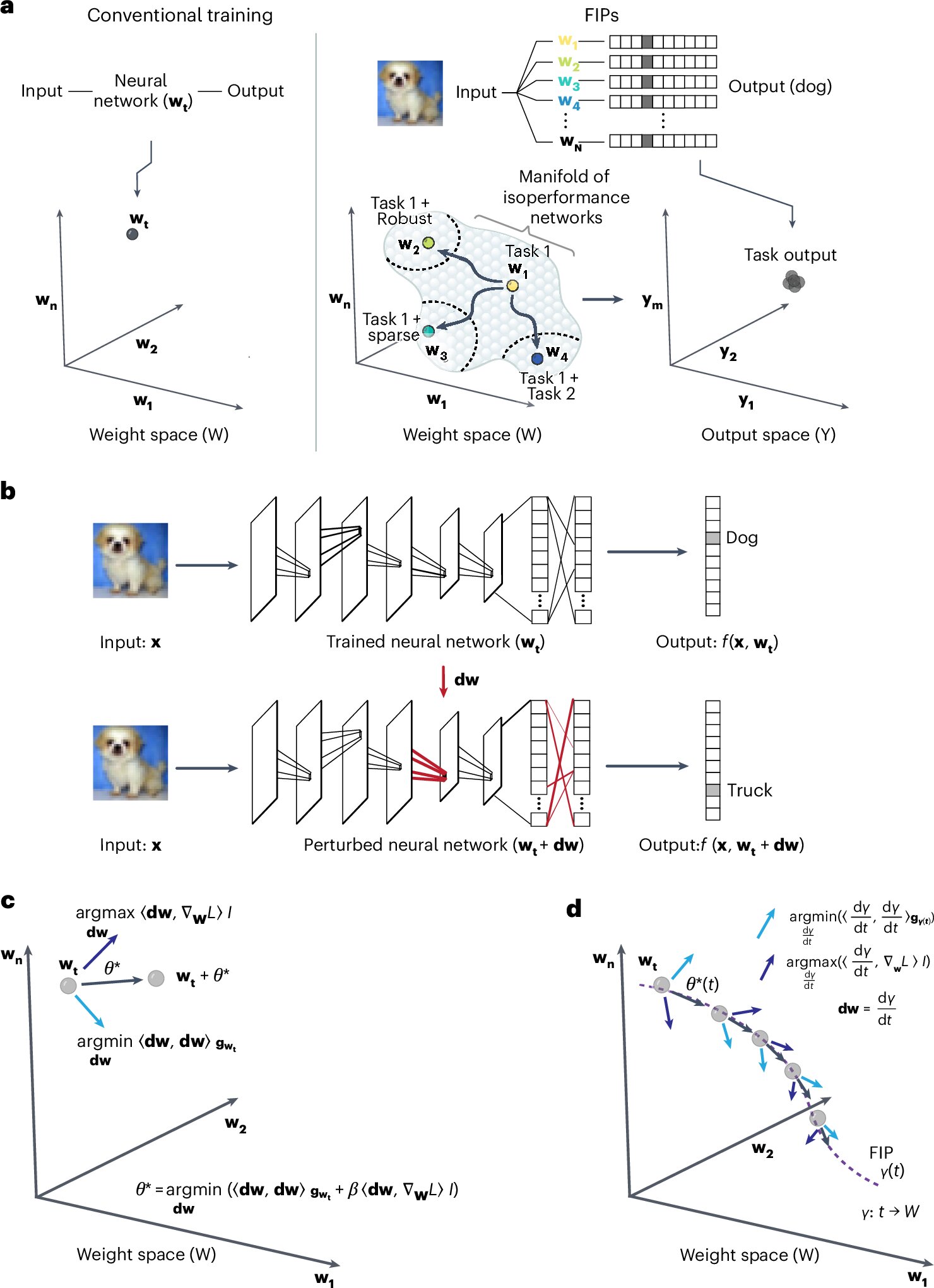
Differential geometric framework for constructing FIPs in weight space. ALeft: Conventional training on a task finds a single trained network (wt) solution. Right: the FIP strategy discovers a subvariety of isoperformance networks (w1, w2…wN) for a task of interest, allowing the efficient search for networks with adversarial robustness (w2), sparse networks with high task performance (w3) and to learn several tasks without forgetting (w4). bTop: a CNN trained with a weight configuration (wt), represented by lines connecting different layers of the network, accepts an input image x and produces a ten-element output vector, f(x, wt). Bottom: disruption of network weights by dw gives rise to a new network with weight configuration wt+ dw with a modified output vector, f(x, wt+ dw), for the same entry, x. cFIP algorithm identifies weight disturbances θ* which minimize the distance traveled in the output space and maximize the alignment with the gradient of a secondary objective function (∇wL). The light blue arrow indicates a ϵ– norm weight disturbance which minimizes the distance moved in the exit space and the dark blue arrow indicates a ϵ-perturbation of the weight of the norm which maximizes the alignment with the gradient of the objective function, L(x, w). The secondary objective function L(x, w) is varied to solve distinct machine learning problems. dThe path sampling algorithm defines the FIPs, y(t), through the iterative identification of ϵ-disturbances of standards (θ*(t)) in weight space. Credit: Intelligence of natural machines (2024). DOI: 10.1038/s42256-024-00902-x
Neural networks have a remarkable ability to learn specific tasks, such as identifying handwritten digits. However, these models often experience “catastrophic forgetting” when taught additional tasks: they may successfully learn the new tasks, but “forget” how to complete the original. For many artificial neural networks, such as those that guide self-driving cars, learning additional tasks therefore requires being completely reprogrammed.
Biological brains, on the other hand, are remarkably flexible. Humans and animals can easily learn to play a new game, for example, without having to relearn how to walk and talk.
Inspired by the flexibility of human and animal brains, Caltech researchers have developed a new type of algorithm that allows neural networks to be continually updated with new data that they can learn from without having to start from scratch. The algorithm, called the functionally invariant path (FIP) algorithm, has wide-ranging applications, from improving online store recommendations to fine-tuning self-driving cars.
The algorithm was developed in the laboratory of Matt Thomson, assistant professor of computational biology and researcher at the Heritage Medical Research Institute (HMRI). The research is described in a new study published in the journal Intelligence of natural machines.
Thomson and former graduate student Guru Raghavan, Ph.D. were inspired by neuroscience research conducted at Caltech, particularly in the laboratory of Carlos Lois, research professor of biology. Lois studies how birds can rewire their brains to relearn how to sing after brain injury. Humans can do it too; People who have suffered brain damage from a stroke, for example, can often make new neural connections to relearn everyday functions.
“This is a multi-year project that started with the basic science of how the brain learns flexibly,” says Thomson. “How can we give this ability to artificial neural networks? »
The team developed the FIP algorithm using a mathematical technique called differential geometry. The framework allows you to modify a neural network without losing previously encoded information.
In 2022, with the guidance of Caltech Entrepreneur-in-Residence Julie Schoenfeld, Raghavan and Thomson launched a company called Yurts to further develop the FIP algorithm and deploy large-scale machine learning systems to solve many different problems. Raghavan co-founded Yurts with industry professionals Ben Van Roo and Jason Schnitzer.
Raghavan is the first author of the study. In addition to Raghavan and Thomson, Caltech co-authors are graduate students Surya Narayanan Hari and Shichen Rex Liu, as well as collaborator Dhruvil Satani. Bahey Tharwat of Alexandria University in Egypt is also a co-author. Thomson is an affiliated faculty member at Caltech’s Tianqiao and Chrissy Chen Neuroscience Institute.
More information:
Guruprasad Raghavan et al, Designing flexible machine learning systems by traversing functionally invariant paths, Intelligence of natural machines (2024). DOI: 10.1038/s42256-024-00902-x
Provided by California Institute of Technology
Quote: Overcoming “catastrophic forgetting”: a brain-inspired algorithm allows neural networks to retain knowledge (October 9, 2024) retrieved October 9, 2024 from
This document is subject to copyright. Except for fair use for private study or research purposes, no part may be reproduced without written permission. The content is provided for informational purposes only.

{kind=link}