

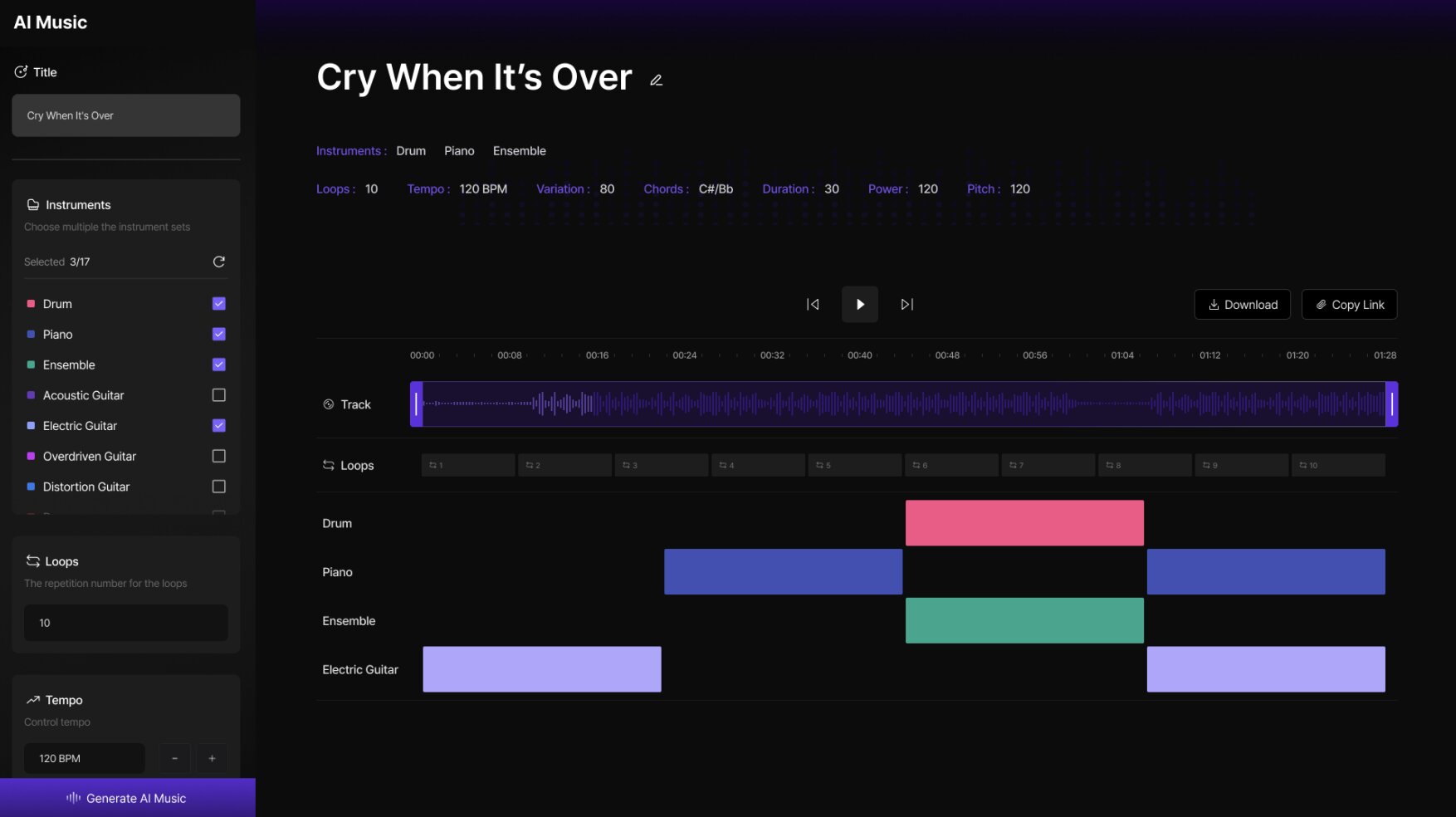
Screenshot of the team’s system demo showing its user interface. Credit: Han et al.
Artificial intelligence (AI) has opened up exciting new opportunities for the music industry, for example, by enabling the development of tools capable of automatically generating specific musical compositions or instrument tracks. Yet most existing tools are designed for use by musicians, composers, and music producers, not non-expert users.
LG AI Research researchers recently developed a new interactive system that allows any user to easily translate their ideas into music. This system, described in an article published on arXiv preprint server, combines a decoder-only autoregressive transformer trained on music datasets with an intuitive user interface.
“We introduce the demonstration of symbolic music generation, focusing on providing short musical motifs that serve as the central theme of the narrative,” Sangjun Han, Jiwon Ham and colleagues wrote in their paper. “For generation, we adopt an autoregressive model that takes music metadata as input and generates 4 bars of multi-track MIDI sequences.”
The transformer-based model that underpins the team’s symbolic music generation system was trained on two music datasets, namely the Lakh MIDI dataset and the MetaMIDI dataset. Collectively, these datasets contain more than 400,000 MIDI (musical instrument digital interface) files, which are data files containing various information about musical tracks (e.g., notes played, note duration, speed at which they are played).
To train their model, the team converted each MIDI file into a musical event representation (REMI) file. This specific format encodes MIDI data into tokens representing various musical characteristics (e.g. pitch and velocity). REMI files capture the dynamics of music in a way that is particularly favorable for training AI models for music generation.
“During training, we randomly remove tokens from music metadata to ensure flexible control,” the researchers wrote. “It offers users the freedom to select input types while retaining generative performance, allowing greater flexibility in musical composition.”
In addition to developing their transformer-based model for symbolic music generation, Han, Ham and their colleagues created a simple interface that would make it accessible to both expert and non-expert users. This interface currently consists of a sidebar and a central interactive panel.
In the sidebar, users can specify which aspects of the music they want the model to generate, such as which instruments should play and the tempo of the song. Once the model has generated a song, it can edit the track in the central panel, for example by removing/adding instruments or adjusting the time it will start playing music.
“We validate the effectiveness of the strategy through experiments in terms of model capacity, musical fidelity, diversity, and controllability,” Han, Ham, and colleagues wrote. “Additionally, we enlarge the model and compare it with other music generation models through a subjective test. Our results indicate its superiority in terms of control and music quality.”
The researchers found that their model worked very well and could reliably generate up to 4 bars of music based on user specifications. In their future studies, they could further improve their system by extending the length of music tracks their model can create, expanding the specifications users can give, and further improving the system’s user interface.
“Our model, trained to generate 4 measures of music with global control, has limitations in terms of extending music duration and controlling local elements at the measure level,” the researchers wrote. “However, our attempts are important to generate high-quality musical themes that can be used in a loop.”
More information:
Sangjun Han et al, Flexible control in symbolic music generation via music metadata, arXiv (2024). DOI: 10.48550/arxiv.2409.07467
arXiv
© 2024 Science X Network
Quote: A new model for symbolic music generation using musical metadata (October 1, 2024) retrieved October 1, 2024 from
This document is subject to copyright. Except for fair use for private study or research purposes, no part may be reproduced without written permission. The content is provided for informational purposes only.

{kind=link}