

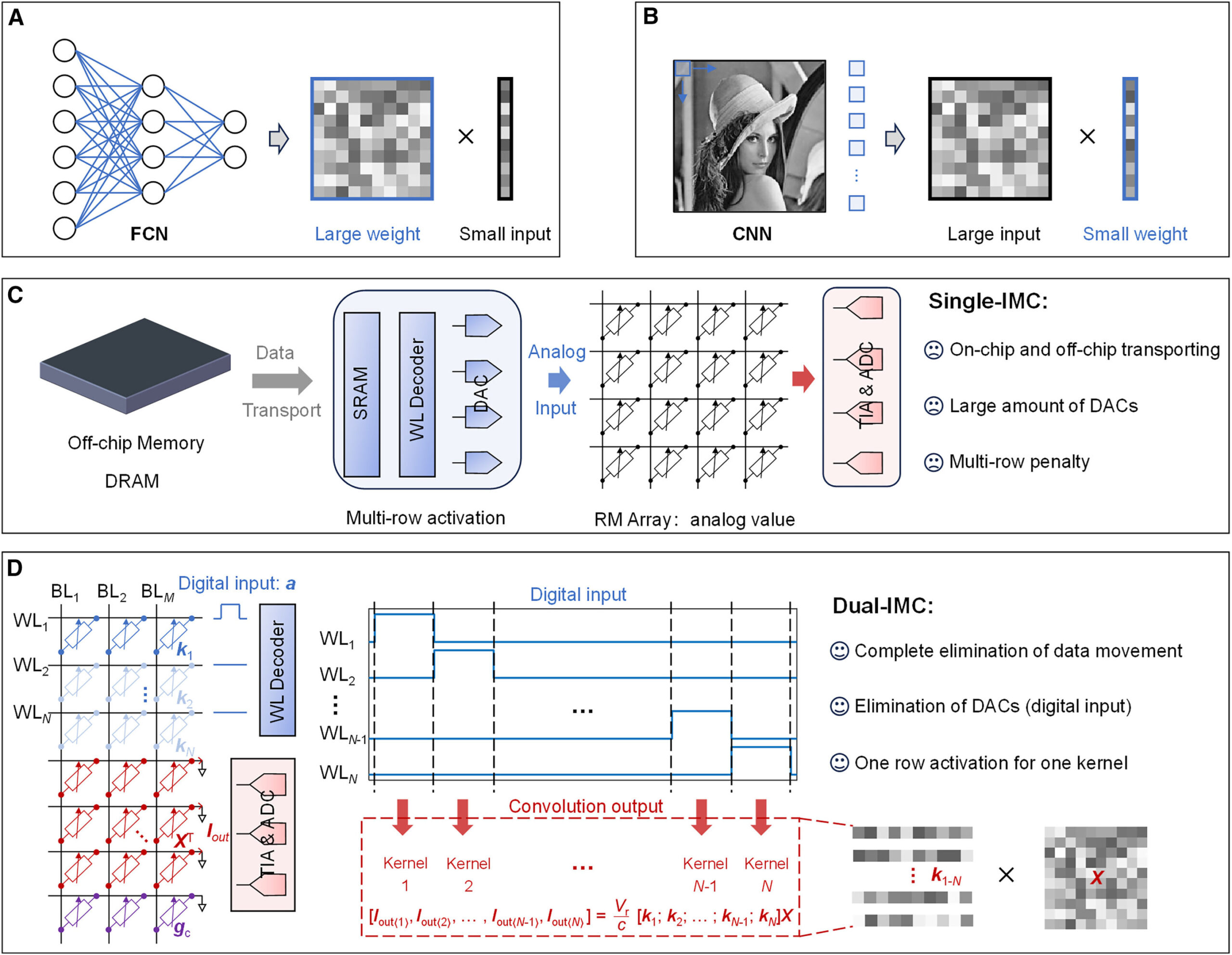
Single BMI and double BMI. Credit: Device (2024). DOI: 10.1016/j.device.2024.100546
Artificial intelligence (AI) models like ChatGPT run on algorithms and have a big appetite for data, which they process through machine learning, but what about the limits of their data processing capabilities ? Researchers led by Professor Sun Zhong from the School of Integrated Circuits and the Institute of Artificial Intelligence at Peking University set out to solve the von Neumann bottleneck that limits data processing.
In their article published in the journal Device On September 12, 2024, the team developed the dual-IMC (in-memory computing) system, which not only accelerates the machine learning process, but also improves the energy efficiency of traditional data operations.
When creating algorithms, software engineers and computer scientists rely on data operations known as matrix-vector multiplication (MVM), which support neural networks. A neural network is a computer architecture often found in AI models that mimics the functioning and structure of a human brain.
As the scale of data sets increases rapidly, computing performance is often limited by data movement and speed mismatch between data processing and transfer. This is called the von Neumann bottleneck. The conventional solution is a single-memory computing system (single IMC), in which the weights of the neural network are stored in the memory chip while the inputs (such as images) are provided externally.
However, the disadvantage of single IMC lies in the switching between on-chip and off-chip data transport, as well as the use of digital-to-analog converters (DACs), which result in a large circuit footprint and power consumption. high energy.
Dual in-memory computation enables fully in-memory MVM operations. Credit: Device (2024). DOI: 10.1016/j.device.2024.100546
To fully exploit the potential of the IMC principle, the team developed a dual IMC scheme that stores both the weight and the input of a neural network in the memory array, thereby performing data operations entirely in memory.
The team then tested dual IMC on resistive random access memory (RRAM) devices for signal recovery and image processing. Here are some advantages of the dual IMC scheme when applied to MVM operations:
- Greater efficiency is achieved through all-in-memory calculations, saving time and energy with off-chip dynamic random access memory (DRAM) and on-chip static random access memory (SRAM).
- Computing performance is optimized because data movement, which was a limiting factor, is eliminated using an all-in-memory method.
- Lower production cost due to elimination of DACs, required in the single IMC system. This also means savings on chip area, computing latency and power requirements.
With increasing demand for data processing in today’s digital age, discoveries made in this research could lead to new breakthroughs in computer architecture and artificial intelligence.
More information:
Shiqing Wang et al, Double in-memory calculation of matrix-vector multiplication to accelerate neural networks, Device (2024). DOI: 10.1016/j.device.2024.100546
Provided by Peking University
Quote: Computing pattern accelerates machine learning while improving energy efficiency of traditional data operations (September 26, 2024) retrieved September 26, 2024 from
This document is subject to copyright. Except for fair use for private study or research purposes, no part may be reproduced without written permission. The content is provided for informational purposes only.
{kind=link}