

Machine learning approaches to predict the behavior of novel trace substances. Credit: Korea Institute of Science and Technology (KIST)
Global consumption of pharmaceuticals is increasing rapidly every year, reaching 4 billion doses in 2020. As more pharmaceuticals are metabolized by the human body and enter sewage treatment plants, the quantity and the types of trace substances they contain are also increasing. .
When these trace substances enter rivers and oceans and are used as water sources, they can cause harmful effects on the environment and human health, including carcinogenesis and disruption of the endocrine system. Therefore, technologies are needed to quickly and accurately predict the properties and behavior of these trace substances, but the analysis of unknown trace substances requires expensive equipment, trained experts and a lot of time.
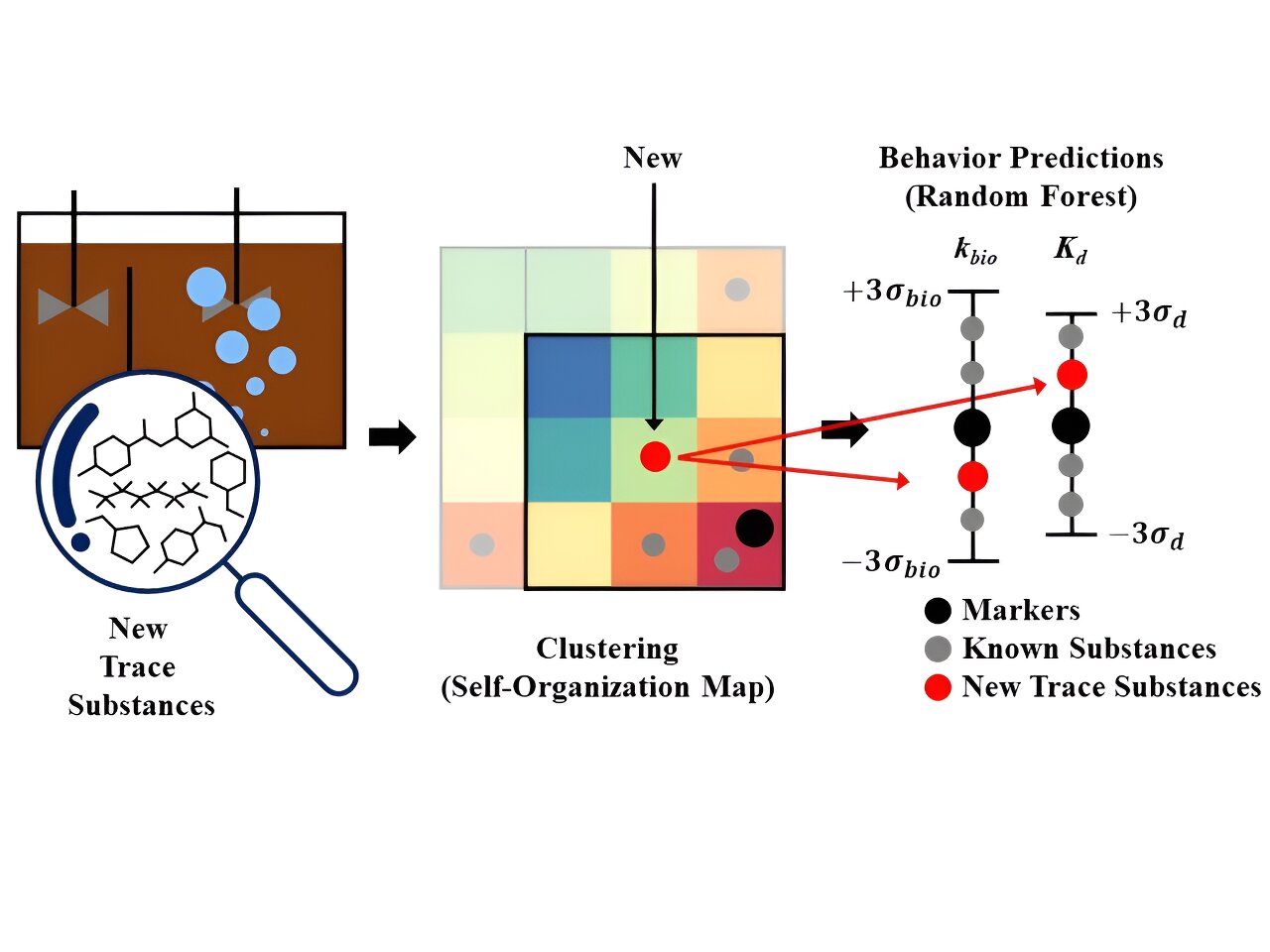
A team from the Korea Institute of Science and Technology (KIST) led by Hong Seok-won, director of the Water Resources and Cycle Research Center, and Son Moon, senior researcher, developed technology to classify emerging trace substances based on their physicochemical properties. and predict their concentrations using artificial intelligence technology based on clustering and prediction.
The researchers used self-organizing maps, an AI technique that groups data into maps based on their similarities, to classify 29 known trace substances, including medicinal compounds and caffeine, based on information such as physicochemical properties, functional groups and biological reaction mechanisms. The research is published in the journal npj Clean water.
Random forests, a machine learning technique that classifies data into subsets, were then constructed to predict the properties and concentration changes of new trace substances.
If a new trace substance belongs to a group in the self-organizing map, the properties of other substances in that group can be used to predict how the properties and concentration of the new trace substance will change.
Following the application of this clustering and prediction AI model (self-organizing map and random forest) to 13 new trace substances, the prediction accuracy of approximately 0.75 was excellent, far exceeding the accuracy of 0.40 prediction of existing AI techniques using biological information.
Compared with traditional formula-based prediction methods, the KIST research team’s data-driven analysis model has the advantage of only capturing the physicochemical properties of trace substances and effectively identifying how the concentration of new Trace substances will change in the wastewater treatment process through grouping with substances with similar data.
Additionally, the data-driven AI model can be used in the future to predict the concentration of new substances such as drugs that cause social concerns.
“It can be applied not only to wastewater treatment plants, but also to most water treatment-related facilities where new trace substances exist, and can provide rapid and accurate data in the development process policies for associated regulations,” said Dr. Seokwon. Hong and Dr. Moon Son of KIST.
“As it uses machine learning technology, the prediction accuracy will improve as relevant data is accumulated.”
More information:
Seung Ji Lim et al, Clustering of micropollutants and estimation of sorption and biodegradation rate constants using machine learning approaches, npj Clean water (2023). DOI: 10.1038/s41545-023-00282-6
Provided by the National Science and Technology Research Council
Quote: Researchers quickly and easily predict concentrations of emerging contaminants in wastewater using AI (January 23, 2024) retrieved January 23, 2024 from
This document is subject to copyright. Apart from fair use for private study or research purposes, no part may be reproduced without written permission. The content is provided for information only.

{kind=link}